paper:Icentia11K: An Unsupervised Representation Learning Dataset for Arrhythmia Subtype Discovery,https://arxiv.org/pdf/1910.09570
code: https://github.com/shawntan/icentia-ecg
datasets: https://academictorrents.com/details/af04abfe9a3c96b30e5dd029eb185e19a7055272
这篇论文指出了基于心电信号进行心率分类这个任务,作者采取了半监督学习的方式,对以往已经取得不错结果的监督学习方式发起了挑战。同时,作者还公开了一个数据集。代码部分主要是对各种机器学习方法进行分类效果的评估。
这里着重看一看代码中关于自编码器的部分。
自编码器
结构
自编码器其实是一类特殊的前馈神经网络。它所做的工作可以简单概括为:将输入复制到输出。除开常规的输入层$\mathbf{x}$和输出层$\mathbf{y}$,它往往还包含了隐藏层$\mathbf{h}$;其结构包括了两个部分:
- 编码器(Encoder),表示为一个函数,将输入层$\mathbf{x}$映射到隐藏层$\mathbf{h}$:$\mathbf{h}=f(\mathbf{x})$
- 解码器(Decoder),表示为一个函数,将隐藏层$\mathbf{h}$映射到输出层$\mathbf{y}$:$\mathbf{y}=g(\mathbf{h})$
那么,自编码器模型整体可以描述为
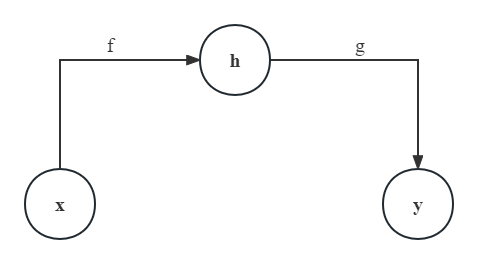
如果只是一味地让自编码器的输出$\mathbf{y}$和输入$\mathbf{x}$完全相同,这毫无疑问舍近求远失去了意义。一般地,自编码器中更加关注编码器的输出结果,即隐藏层$\mathbf{h}$。比如,如果$\mathbf{h}$的维度比$\mathbf{x}$小,编码器就相当于学习到了原始输入的更加显著的特征。这种想法,与诸如主成分分析一般的降维算法有些相似。
训练
自编码器也是前馈神经网络,它的训练和一般的前馈神经网络很类似,即定义损失函数、然后梯度下降,只不过,这是一种无监督的学习方式,无需额外的标注工作,因为它的学习目标就是原始的输入数据。更一般地,可以采取小批量的随机梯度下降,不断地逼近要学习的原始数据。
损失函数用数学语言描述为
其中具体的损失函数$\mathcal{L}$因情况而定,比如可以是均方差$MSE$。
实战代码
接下来,借助现有的代码,理解一下自编码器以及训练过程。其实,正如前面提到过的,这个过程和一般的前馈神经网络很像。
准备数据
准备数据始终是第一步,这一部分的代码主要在train_autoencoder.py中。
# train_autoencoder.py
def data_stream(filenames, shuffle=True, batch_size=16):
'''
用于读取文件,返回可以拿来训练的数据用
filenames: list,文件名列表
shuffle: 是否打乱
batch_size: 批量,默认为16
'''
stream = data_io.stream_file_list(
filenames,
buffer_count=20,
batch_size=batch_size,
chunk_size=1,
shuffle=shuffle
)
stream = data_io.threaded(stream, queue_size=5)
return stream主函数中将数据集进行了划分,比例为9:1。
directory = 'icentia-ecg\datasets' # 这里是自己定义的数据集存放位置(相对路径)
filenames = [ directory + "\\%05d_batched.pkl.gz" % i
for i in range(21) ] # 这里自己调整,不用全部的数据集,只使用编号00000到00020的数据集
train_count = int(len(filenames) * 0.9)
# 划分训练集和验证集
train_filenames = filenames[:train_count]
valid_filenames = filenames[train_count:]搭建自编码器
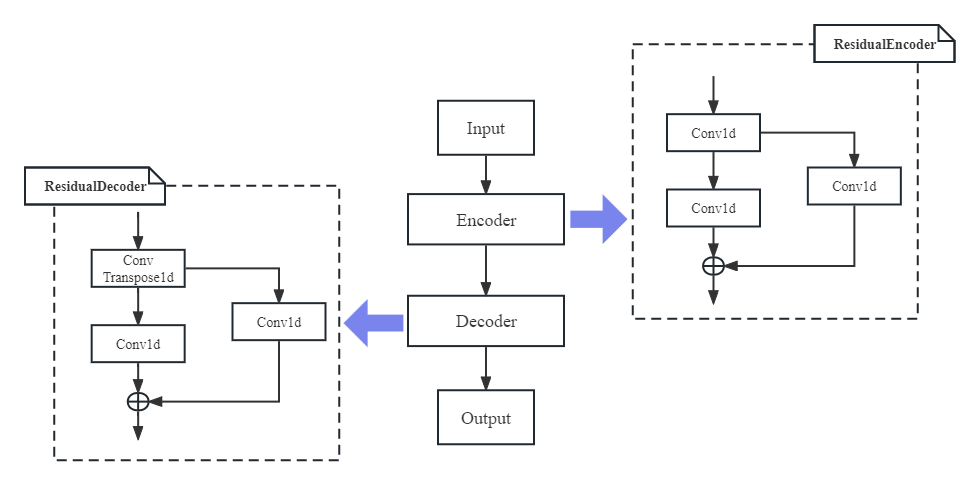
关于自编码器的模型的代码主要在model.py中的class Autoencoder,这里限于篇幅不贴出来,而是尝试绘制了自编码器的结构示意图。
# model.py/Autoencoder
def encode(self, input_flat):
encoding_1 = self.frame_bn(self.autoencode_1.encode(input_flat))
return encoding_1
def decode(self, encoding):
output = self.autoencode_1.decode(encoding)
return output
def forward(self, input):
input = (input - self.mean) / self.std
input_flat = input.view(-1, 1, input.size(-1))
output = self.decode(self.encode(input_flat))
output = output.view(input.size())
# input为原始输入,output为自编码器的输出,直接计算损失
loss = torch.sqrt(torch.mean((output - input)**2))
# loss = torch.mean(abs(output - input))
return loss代码中的自编码器结构还是很简单的,其实这里的编码器和解码器都只是一个类似残差块的结构(代码中的ResidualEncoder、ResidualDecoder),但是注意,实际上Autoencoder中的二级结构为ConvAutoencoder,只不过ConvAutoencoder这里仅由一个ResidualEncoder和一个ResidualDecoder构成。总的来说,编码器、解码器结构十分明显,它们结构上呈现出对称感,共同完成将原始输入映射到隐藏层编码,然后再映射回去的任务。
将程序运行的结果截图如下。

另外,loss = torch.sqrt(torch.mean((output - input)**2))可以看出,这里的损失函数选用的是均方根误差;学习的对象也正是原始的输入数据input,正是自编码器的初衷。
开启训练
再次回到train_autoencoder.py。在正式开启训练之前,创建模型,定义好优化器、参数等等准备工作。
# train
model = Autoencoder(0, 1)
# valid_data = torch.from_numpy(signal_data_valid).cuda()[:, None, :]
for p in model.parameters():
if p.dim() > 1:
torch.nn.init.xavier_uniform_(p)
# model = torch.load('model.pt')
model = model.cuda()
parameters = model.parameters()
# 优化器
optimizer = optim.Adam(parameters, lr=1e-3) # , weight_decay=1e-6)
# optimizer = optim.SGD(parameters, lr=0.05, momentum=0.999)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(
optimizer, mode='min',
factor=0.5, patience=10, verbose=True, threshold=0.0001,
threshold_mode='rel', cooldown=0, min_lr=1e-6, eps=1e-08
)
# 训练轮数
epochs = 10
# batch_count = signal_data_batched.shape[0] // batch_size
best_loss = np.inf
i = 0
input = None开启训练。
# train_autoencoder.py
for epoch in range(epochs):
running_loss = 0.0
time_step_count = 0
for data in data_stream(train_filenames):
# get the inputs
input = torch.from_numpy(data.astype(np.float32)).cuda()
# zero the parameter gradients
# forward + backward + optimize,model(input)直接返回输出和原始输入之间的损失
loss = model(input)
# print(loss)
if i % 4 == 0:
loss.backward()
torch.nn.utils.clip_grad_norm_(parameters, 10.)
optimizer.step()
optimizer.zero_grad()
# print statistics
total_samples = input.numel()
running_loss += loss.detach().item() * total_samples
time_step_count += total_samples
i += 1
if i % report_every == 0: # print every 500 mini-batches
print('[%d, %5d] loss: %.3f' %
(epoch, i, running_loss / time_step_count))
running_loss = 0.0
time_step_count = 0
if i % (report_every * 10) == 0:
# print()
# print("REPORTING")
# print()
model.eval()
with torch.no_grad():
total_loss = 0.
count = 0
for data in data_stream(valid_filenames[:20], shuffle=False,
batch_size=32):
# get the inputs
input = torch.from_numpy(data.astype(np.float32)).cuda()
loss = model(input)
# print(loss)
total_loss += loss.data.item()
count += 1
valid_loss = total_loss / count
if valid_loss < best_loss:
print("Best valid loss:", valid_loss)
with open('model.pt', 'wb') as f:
torch.save(model, f)
best_loss = valid_loss
else:
print("Valid loss:", valid_loss)
random.shuffle(valid_filenames)
scheduler.step(valid_loss)
model.train()


