算法背景
SVM有三宝:间隔、对偶、核技巧。
宝一:间隔
从间隔角度来看,支持向量机可以分为三种:
- 硬间隔支持向量机
- 软间隔支持向量机
- 核支持向量机
硬间隔SVM
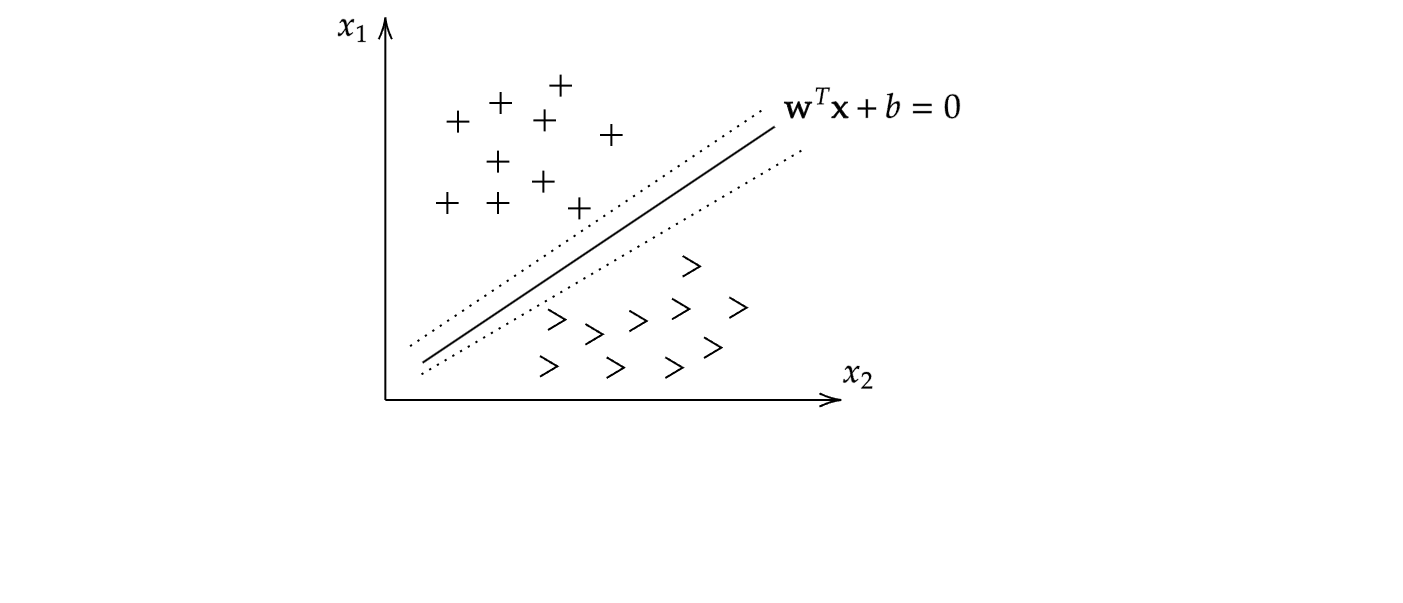
给定一组样本集合:$\{ (\mathbf{x}^{(1)}, y^{(1)}), (\mathbf{x}^{(2)}, y^{(2)}), \cdots, (\mathbf{x}^{(N)}, y^{(N)}) \}$,其中$\mathbf{x}^{(i)}\in \mathbb{R}^p, y^{(i)}\in \{-1,1\}$。
上图是二维数据情况下,支持向量机对样本的二分类的直观描述:找到一条超平面,将两类样本完全分开。而满足这个条件的超平面其实是有无数个的,究竟该选择哪一个呢?有如下限制:选取间隔最大的超平面,它恰好能够将不同类别完全分开。
我们先将“间隔”按下不表,来用简洁的数学语言描述一下最简单的支持向量机:
注意这里我们将条件
统一成一个
接下来我们关注一下所谓的“间隔”$\mathrm{margin}$。间隔实际上指的是所有的点到该超平面的距离($\mathrm{dis}$)的最小值。由点到直线距离公式,可知样本$(\mathbf{x}^{(i)},y^{(i)})$到超平面$\mathbf{w}^T\mathbf{x}+b=0$的距离为
借助标签,进一步将$\mathrm{dis}$绝对值去除:
故支持向量机描述为:
接下来我们继续推导目标函数,将形式简化:
这个式子很有意思。首先一定有
事实上,$\gamma$取值并不重要,因为对$\mathbf{w},b$的等比例缩放并不会影响到其所表示的超平面,换言之,下面两个超平面其实是完全等价的:
因此,为方便后续运算,令$\gamma=1$,进而得到待优化的目标函数与约束条件
而通常我们习惯求解最小优化问题,于是最终的支持向量机描述为
接下来我们尝试求解这个带约束优化问题。
求解约束优化问题
对于约束优化问题,引入拉格朗日函数,将其转化为无约束优化问题:
其中$\Lambda=[\lambda_1,\lambda_2,\cdots,\lambda_N], \mathbf{w}=[w_1,w_2,\cdots,w_N]$
根据强对偶条件,该优化问题也可等价于:
拉格朗日函数为
关于约束优化问题(8)(9)(10)之间的等价性,下面从逻辑分析角度进行简单的分析(并非严格的数学证明)。
(9)到(8)
相比于(8),(9)实际上是一个无约束问题。我们分别考虑下面两种情况:
- $\exists i \in \{1,2,\cdots,N\}, s.t. 1-y^{(i)}(\mathbf{w}^T\mathbf{x}^{(i)}+b)>0$
- $\forall i \in \{1,2,\cdots,N\}, 1-y^{(i)}(\mathbf{w}^T\mathbf{x}^{(i)}+b) \leqslant 0$
对于第一情况,显然取$\lambda_i=\infty$,有
对于第二种情况,显然取$\Lambda=\mathbf{0}$,有
综上有
换言之,(9)通过改变待优化目标函数的形式,将(8)中的约束条件隐式地包含了,故而不再需要额外的约束条件。
(9)和(10)
这两个约束优化问题互为对偶问题。且此时待优化函数是凸函数,满足强对偶条件,因此它们等价。
对偶问题
原问题DP如下
其对偶问题LP为
记DP问题的最优解为$d^$,LP问题的最优解为$p^$,则有
上式也称为弱对偶条件。
而当约束函数为凸函数时,有$d^=p^$,此时称为强对偶。
求解最小优化问题
我们对优化问题(10)进行求解:
其中
先求解最小优化问题:显然只需对$\mathbf{w},b$求偏导即可。
令偏导数为零,得到
接下来,将上式代入$\mathcal{L}$,整理得
到这里,我们得到如下等价的优化问题:
KKT条件
转化到上述优化问题后,可以通过一些特定软件求解参数$\lambda_1,\lambda_2,\cdots,\lambda_N$,进而将该问题解决。下面介绍另一部分非常重要的内容:KKT条件。
由于带约束优化问题满足强对偶,因此它满足KKT条件。而KKT条件包括原始可行性、对偶可行性和互补松弛条件,即
上述条件中,第一个式子在前文已经利用到,得到的结果即(21)。下面来思考一下第二个式子的含义:事实上,第二个式子(互补松弛条件)揭示了这样的一个真相:只有位于超平面$\mathbf{w}^T\mathbf{x}+b=1$和$\mathbf{w}^T\mathbf{x}+b=-1$上的样本点才对优化目标函数的值产生了影响(否则对应的拉格朗日乘子$\lambda_i$均为零)。多提一句,我们把这样的点称为支持向量,这正是算法模型名称的由来。
关于支持向量
事实上,我们前面通过限定函数间隔定义过几何间隔:也就是说,所有样本点中,与决策超平面$\mathbf{w}^T\mathbf{x}+b=0$最近的点与之距离为$\frac{1}{||w||}$。可以利用点到距离公式验证,这样的点(也即支持向量)所在超平面就是$\mathbf{w}^T\mathbf{x}+b=1$以及$\mathbf{w}^T\mathbf{x}+b=-1$。
那么,一定有
故而有
结合(21),得到最终的最优解
软间隔SVM
其实到这里,已经注意到了:上面的SVM实际上是找到一个最优的决策超平面将样本严格分开,因此它被称为硬间隔SVM。与之相对地,如果构建的SVM允许分类中出现一点点错误,以此来换取更好的泛化能力,这种模型则称为软间隔SVM。
在硬间隔SVM中,约束条件是严格的:
而软间隔的引入实际上是对原来的目标函数加上一个惩罚项。首先,上述约束条件被放松,不再严格要求成立。另外需要引入一个参数$\xi_i$用于衡量这种“犯错误的程度”,即当$y^{(i)}(\mathbf{w}^T\mathbf{x}^{(i)}+b)<1$时,
注意,$\xi_i \geqslant 0$。
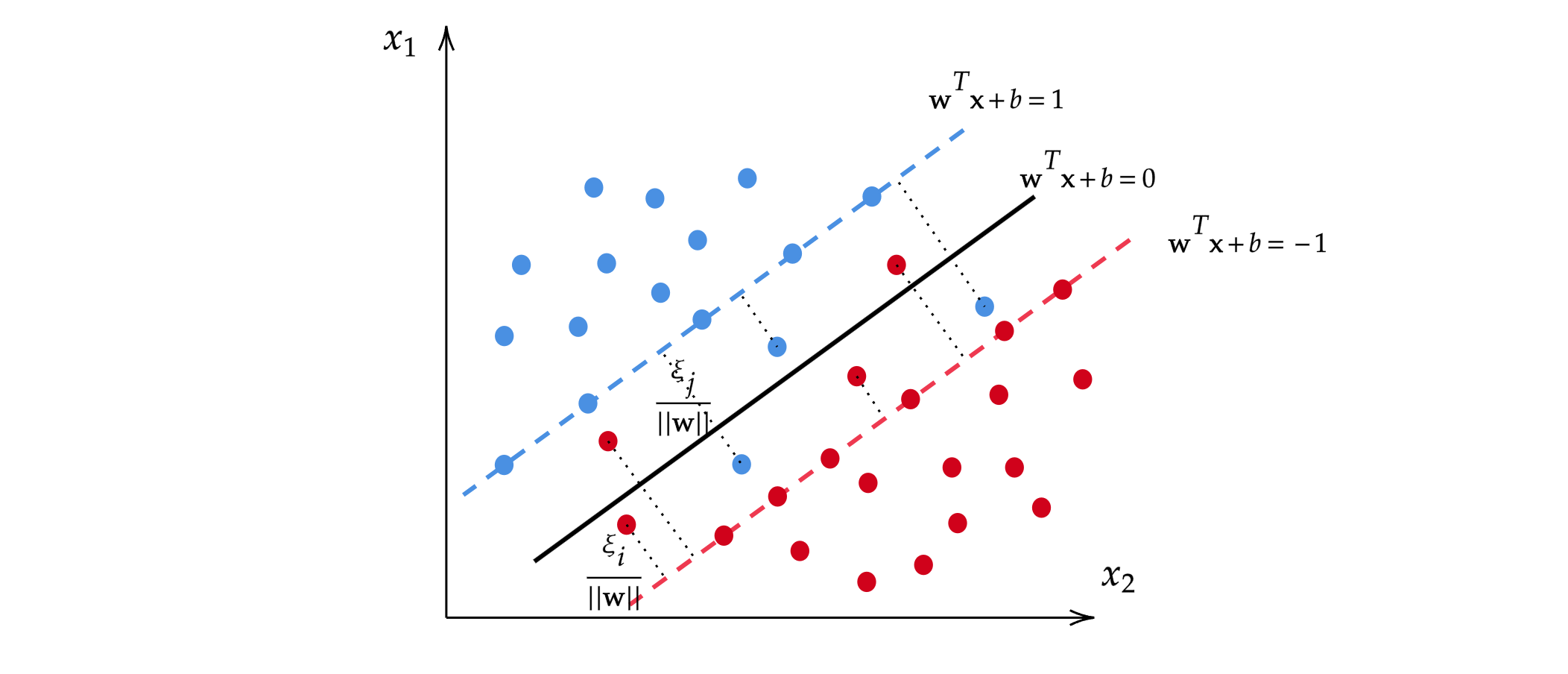
显然,$\xi_i$越大,表明样本“违反”原严格条件的程度越大,越应该受到惩罚。我们在原硬间隔SVM的目标函数基础上,添加一个带有惩罚系数$\mathcal{C}$的惩罚项,于是得到最终的软间隔SVM优化问题:
To be continued…



